寇传华 张媛媛
(青岛理工大学信息与控制工程学院 青岛 266520)
人类复杂疾病的发生和发展通常不是由单一因素引起的,而是由多种因素相互作用引起的功能性障碍[1~2]。因此,基于网络模型挖掘复杂疾病生物标志物是复杂疾病相关研究的重要内容[3~4]。然而,目前基于网络模型挖掘疾病标记物的研究中很少涉及到对所构建网络模型真实性的评估。
DNA 甲基化作为一种重要的表观遗传修饰,在生物体的生命过程中,环境会影响DNA 甲基化水平从而调控基因表达出不同的表型。因此,基于甲基化数据识别癌症致病因子有助于在早期发现疾病并对疾病治疗方案给出建议[5]。同时,研究基因间甲基化水平变化的相关性可以在癌症早期阶段找到与癌症相关的基因模块。目前,基于DNA甲基化数据并利用其数据特点,出现了大量基于网络模型的直接关联所有CpG 位点对的方法[6~7]。因为每个基因对应多个甲基化位点并且不同基因对应的甲基化位点数目是不同的,所以构建基因网络的关键在于如何把CpG 位点的甲基化水平映射到基因层面上。根据不同的融合方法,可以将其分为基于平均值的方法[6]、总体值的方法[7]和差异得分的方法[8]。Ma 等[6]在DNA 甲基化网络的构建中,将基因中一些位点的平均甲基化水平作为基因的甲基化水平,用Pearson 相关系数(PCC)来测量基因之间的相关性。Bartlett 等[7]基于典型相关分析(CCA)的方法构建甲基化基因网络来识别与癌症相关的模块;
West 等[8]提出的EpiMod 方法,该方法将表型上每对基因差异得分(diffscore)的平均值作为边缘权重来识别与年龄相关的甲基化模块。综上所述,根据DNA 甲基化数据的特点,在基因层面上采用不同测度的多位点甲基化融合方法可以得到不同的基因网络[9~10],不同网络的拓扑结构会影响疾病相关生物标志物的识别[11]。
在本文中,受Nguyen 等提出扰动聚类算法的启发[12],我们提出了ENCPer 方法。该方法评估用不同的方法构建的基于DNA 甲基化数据的基因网络的稳定性(图1)。我们实验的基本过程如下:首先,基于真实的DNA 甲基化数据用不同的方法构建基因网络。其次,将高斯噪声数据作为扰动加入到真实的DNA 甲基化数据中,最后,重建基于扰动数据的基因网络。为衡量不同网络构建方法的优劣,本文提出了一种网络稳定性度量方法ENCPer,就如何基于DNA甲基化数据构建网络提供建议。

图1 本文框架
2.1 基因加权网络的构建
在获得上述差异甲基化基因后,本文从三个角度:融合数据的平均值,总体值和差异得分构建了基因网络。在本节中描述了三种融合角度下基于PCC,CCA和diffscore基因网络的构建方法。
基于PCC方法的基因加权网络的构建:对于每个基因,将一个基因中所有甲基化位点的平均甲基化水平作为该基因的甲基化水平。对于正常样本和癌症样本,使用PCC 计算两个基因之间的相关性,并分别获得处于正常和癌症状态的两个基因网络邻接矩阵和,然后使用正常和癌症网络对应边之差得到差分网络邻接矩阵ΔMpcc。
基于CCA 方法的基因加权网络的构建:基因X和Y包含不同数量的甲基化位点,用线性组合U1=aT∙X和V1=bT∙Y描述基因。两个基因的相关性由下面公式描述:
cov(U1,V1)是U1和V1的协方差,var(U1) 和var(V1) 分别是U1和V1的方差。在所有可能的线性组合中找出使ρ最大的线性组合的对U1和V1,通过相关性ρ建立基因网络,这三个网络的邻接矩阵分别表示为,和ΔMcca。
基于diffscore 方法的基因加权网络的构建:可以使用某种距离度量(欧氏距离或相对熵)比较肿瘤样本与正常样本之间每个位点的差异,并选择中位数或者平均值作为基因的差异得分(这里使用平均值和中位数),表示为GDS(X)。通过计算基因X和Y之间的权重wXY构造diffscore 差分网络,diffscore 网络的邻接矩阵表示为ΔMdiffscore。公式定义如下:
2.2 显著性计算
本文使用相似性置换的方法来显示差分网络中加权边缘的重要性。首先,对于原始数据中的样本标签进行nperm次置换。其次,每次置换后计算正常样本和癌症样本对应的基因网络和差分网络,差分网络邻接矩阵表示为perm_ΔMmethod。最后,使用下面的公式计算每个边缘权重的p值。
2.3 不同网络的稳定性评价
本文提出了ENCPer 算法,在原始的甲基化数据中随机添加高斯噪声θ,并利用上述三种计算基因间权重的方法重新构造基于扰动数据构建的扰动基因网络。并通过以下定义的累积分布函数(CDF)来评估由这三种方法构建的网络。
公式中I()∙是一个指标函数,E是一组边,wij代表基因i和基因j在不同方法构建的真实网络中网络边缘的权重;
同样地,代表基因i和基因j在不同方法构建的扰动网络中网络边缘的权重。τ是CDF 的阈值,num(E)代表相应网络中的边数。具有最高稳定性的网络将被认为是最接近真实生物系统的网络。
3.1 基于不同方法的网络特征分析
使用PCC[6],CCA[7]和diffscore[8]方法构建在BRCA和COAD数据集上的基因加权网络[11]。根据权度(degree),紧密度(close)和page rank 可以比较在不同网络中对应节点的重要性和不同网络的不同特征。通过对不同网络中的边重叠数目的比较,可以看出根据不同方法构建的基因网络差异性很大(图2)。根据不同网络中节点重要性得分的排序选择前500个基因进行重叠比较(图3)。发现除了在BRCA 数据集上对节点进行基于权度评估中三个网络的交集较大,其他情况下网络的交集较少。这表明用不同方法构建网络对结果的影响很大,所以选择合适的网络构建方法对于了解真实的生物系统或识别与疾病真正相关的标记具有重要意义。
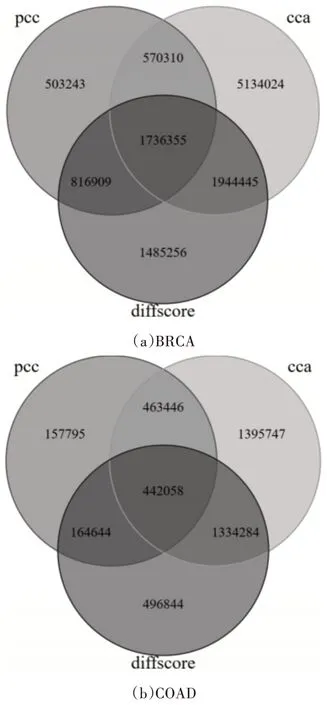
图2 三种不同网络中的边的交集

图3 在不同节点重要性评估中三个网络的重叠
3.2 网络稳定性分析
在BRCA 和CODA 数据集上,分别基于PCC,CCA 和diffscore 方法构建真实基因网络。在这里,我们选择两个距离指标,欧氏距离(Eu)[13]和相对熵(RE)[14]以及均值(mean),中位数(median)两个综合指标来计算基因的差异得分。我们将这四种条件(Eu_mean,Eu_median,RE_mean,RE_median)应用于diffscore 并于PCC 和CCA 方法构建的基因网络进行比较,我们向实际数据中添加了不同的噪声θ=(0.01 ,0.05,0.1,0.2,0.3,0.5 )。根据式(4)对CDF进行计算,通过改变阈值可以得到不同噪声下的四个基因网络的稳定性得分(图4)。

图4 BRCA数据集(左侧)和COAD数据集(右侧)上的三个网络在噪声和阈值下的稳定性评估
通过观察不同网络在不同数据集中的性能,我们发现当τ=0 时,基于CCA 方法构建的基因网络稳定性最差。这可能与以下原因有关:CCA的权重计算方法综合考虑了所有位点的信息,错误地合成了真实信号和噪声,因此对随机添加的噪声敏感。一方面,基于diffscore 方法构建的网络无论使用哪种距离测度和综合指标都具有中等稳定性。基于PCC 的网络虽然在COAD 数据集中具有较高的稳定性,但在BRCA 数据集中稳定性较低。另一方面,在不同的噪声下,基于PCC 和CCA 方法构建的网络具有鲁棒性,基于diffscore 的网络除了根据距离测度和综合指标选择出来的相对熵和均值具有鲁棒性外,其他不具有鲁棒性。因此,结合以上两个方面的分析,基于PCC 的网络和基于diffscore 的网络具有更高的稳定性,并且对噪声的鲁棒性更高。
3.3 疾病相关生物标志物的鉴定
在得到BRCA 和COAD 数据集中表现最稳定的网络后,使用R 语言igraph 包中的cluster_fast_greedy 算法优化模块化得分来得到稠密子图。使用clusterProfiler 包对两个网络中的子图进行KEGG 和GO 富集分析。结果表明,子图中的基因在丰富细胞分化,细胞命运等与疾病相关的GO 术语的同时也丰富了多种疾病的相关通路,例如细胞粘附分子,胃癌和乳腺癌作用等。为了展显最稳定网络的性能,我们与其他网络富集分析的结果进行比较,实验结果表明,在COAD 数据集上基于diff⁃score 方法构建的基因网络中找不到明显的稠密子图;
在基于PCC方法的基因网络中发现了疾病相关富集通路(如皮肤癌、乳腺癌等),但这些富集通路在基于CCA方法的网络中没有发现。
DNA 甲基化是基因组与环境之间的联系,通常在癌症发生的早期阶段发生变化[15]。精确鉴定出与甲基化变化相关的生物标记物可作为早期癌症风险评估的风险因素。此外,由于癌症是多种因素相互作用的结果,所以,构建基于DNA 甲基化的基因网络对于识别癌症相关功能模块具有重要意义。在两个真实数据集BRCA 和COAD 中,我们分别从平均值,总体值和差异得分三种角度使用三种不同的方法构建基因加权网络。使用ENCPer方法评估构建出不同网络的稳定性。通过比较这些网络特性,我们发现不同方法构建的网络有很大的差异,这也充分说明了研究网络稳定性评估策略对于后续工作的重要性。通过对不同网络的稳定性评估,我们发现在BRCA数据集中,基于diffscore方法构建的网络最稳定,而在COAD 数据集中,基于PCC 方法构建的网络最稳定。针对这两个稳定的网络,通过社区检测算法分别获得了两个网络的稠密子图,并对获得的稠密子图进行了GO 和KEGG富集分析,得到的富集分析结果显示了网络结构的生物学意义以及基于扰动算法构建出稳定网络的有效性。
猜你喜欢甲基化位点癌症镍基单晶高温合金多组元置换的第一性原理研究上海金属(2021年6期)2021-12-02体检发现的结节,离癌症有多远?好日子(2021年8期)2021-11-04CLOCK基因rs4580704多态性位点与2型糖尿病和睡眠质量的相关性昆明医科大学学报(2021年3期)2021-07-22二项式通项公式在遗传学计算中的运用*生物学通报(2019年3期)2019-02-17一种改进的多聚腺苷酸化位点提取方法电脑知识与技术(2018年19期)2018-11-01癌症“偏爱”那些人?海峡姐妹(2018年7期)2018-07-27对癌症要恩威并施特别健康(2018年4期)2018-07-03不如拥抱癌症特别健康(2018年2期)2018-06-29SOX30基因在结直肠癌中的表达与甲基化分析癌变·畸变·突变(2015年3期)2015-02-27鼻咽癌组织中SYK基因启动子区的甲基化分析现代检验医学杂志(2015年2期)2015-02-06